
Building an Ethical Policy Analyzer: What ESG Reports Reveal and Conceal
Arnav Satish, Sophomore in Computer Engineering at UC Davis, recaps his work on a Data x Direction Undergraduate Internship Project



In terms of accountability for major corporations, there is no incentive or pressure for companies to consider the environment. Companies that boast about their environmental achievements mainly do it to appease the public and maintain trust in their stockholders. Even at the level of public pressure, there is still some benefit; however, companies can pick and choose what to address, leaving out certain ethical topics. My goal in building this project is to explore ESG (Environmental, Social, and Governance) reports to identify topics that were left out and need to be addressed.
Background & Motivation
I’m a Computer Engineering BS student at the University of California, Davis. I’ve been very interested in computers and hardware ever since I was little. I want to create a project with real-world impact that showcases what I have been learning.
The Data Ethics Research Internship application through Data x Direction was intriguing, so I applied and ended up paired with Program Director Jesse Parent. He encouraged me to find an interesting topic to create something I’m truly passionate about, which led me to considering the nature of evaluating organizations environmental impact and how technology could be used to further this aim.
This led me to being curious about ESGs; I was unfamiliar with this topic at the time, so I began a deep dive into what they are and how they work. ESG reports are documents released by companies that showcase environmental and social impacts. What caught my eye was that almost all major companies publish this sort of document, but they used different formats. After noticing this, I wanted to create a system that regulates these reports.
Motivation: Why ESG Reports?
Originally, I thought that there had to be a company that already does something similar, and I was right. There are scoring frameworks from Yahoo, S&P Global, and other sources, but they were not what I envisioned building. They focused more on investor reports and were scored by private analysts, who did not disclose their process. I wanted something very transparent, with a stronger focus on environmental responsibility.
The more I looked into ESG reports, the more confused I became about the reasoning behind these documents. They seem to be promoting sustainability while being transparent to the audience, but they have a lot of flexibility with how they do it. Since this is technically a voluntary document, they can “cherry-pick” topics they want to highlight while downplaying areas that they don’t address. This lack of enforced structure makes it hard to meaningfully compare companies.
A major corporation can produce a very polished report that gives the appearance of sustainability without the underlying data to back it up. This document comes down to who has the stronger branding and a better team to highlight their initiatives. Just to clarify, I’m not denying the environmental impacts these companies have had; I’m highlighting how they can push a strong sustainability initiative without addressing broader issues.
I considered using Natural Language Processing (NLP) models as a good way to address this issue. Instead of relying on curated narratives and secretive analysis scores, an automated system can analyze the ESG reports and determine what has been addressed/omitted. I envisioned something that could also categorize the topics addressed and evaluate how companies address them.
By shifting ESG reports from being subjective towards a more meaningfully quantified report, I wanted to create something that has a standard format and highlights what companies report on – or what they are leaving out. I was seeking a way to highlight what the ESG Report should have been from the beginning, in making sure these companies actually contribute to improving the environment, or at least offer some reality check on what they are declaring to the broader public.
This became the foundation of my project, in which I envisioned building something that promotes transparency and focuses on the environment rather than financial analysis.
Project “Designing the Policy Analyzer”
Project Goal
The Ethical Policy Analyzer (EPA) was designed to prioritize transparency and interpretability. A core driver was to identify what data was currently available and presented, and what data could or should be available; this contrast would yield an analysis that helped the viewer understand the company’s impact on the world. Doing so in a transparent and standardized way would help move this beyond less clear reporting or investor-driven analysis.
During the development phase, I wanted to consider many dimensions of ESG reporting. This would be crucial to rubric construction, so I started by reviewing extensively the various environmental factors reported or accounted for in the domain of large corporate reporting.
We decided on a preliminary target outcome: a tool that would quickly and transparently or uniformly grade a company’s ESG performance to reveal which metrics the company was doing better at and where it could improve its environmental impact and accountability.
Data & Approach
I started by creating a collection of various ESG reports from FAANG corporations. This data was found directly from the sustainability sections of their websites. Using these documents, I browsed through all the reports to find similarities and formatting structure. I primarily selected Meta and also looked at the historical evolution of ESG reports to see what information they add each year.
There were very mild similarities across the reports; their formatting differed, but they all attempted to answer similar questions. This was one of the leads I had to create a grading rubric to evaluate companies that have prepared sustainability documentation.
Since most of these ESG reports are published as PDFs with various visual effects, tables, and charts, I needed to clean and prepare the data. I solved this by extracting raw text from the PDFs, removing headers, footers, and page numbers, and creating a consistent text section for NLP analysis.
To organize this project’s development, we used a shared GitHub board to track and plan it. We used this as a central place to store and organize the data collected to structure our project.
Designing the Rubric
After data preprocessing, I started thinking about how to structure my rubric and how to account for the different formats and styles of ESG disclosures. We approached this by focusing on the questions and concerns the companies were trying to address with these reports. Through reviewing multiple reports across major companies, we noticed a recurring theme.
Even though the formatting was different, they all addressed similar environmental domains. These common themes formed the foundation, and I also included other areas I think are highly relevant to environmental benefits. Using this, I created six high-level categories:
Energy & Electricity Use
Carbon / GHG Emissions
Water Use
Data Center Efficiency
Forward-Looking Statements & Commitments
Framework Alignment
The first four address measurable environmental impacts, and the last two are on company alignment with ESG frameworks. Since FAANG companies are predominantly technology companies, we selected categories that recur across the companies' ESG reports1. We manually analyzed the sustainability reports and surveyed common disclosure metrics. The final two categories were to show how companies frame their position on sustainability and how much they adhere to recognized reporting structures. This allows us to analyze both the company-professed intentions and their alignment with reporting frameworks.
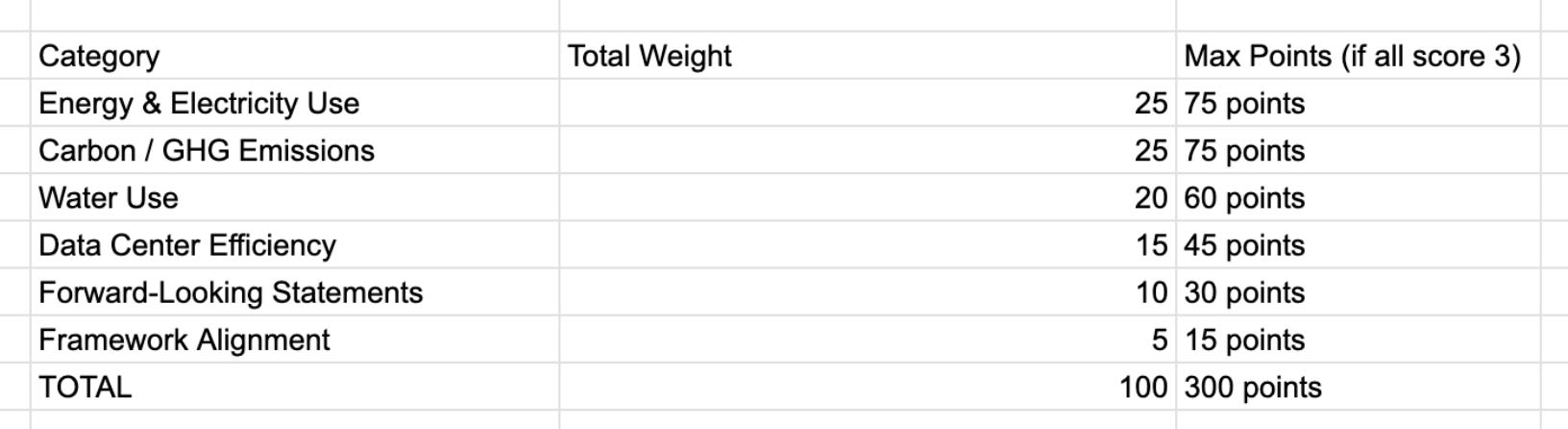
Figure caption: As in the figure above, our weights favored the actual quantifiable metrics, with Energy & Electricity use and Carbon / GHG Emissions as having the highest weight of 25/100, whereas Framework Alignment was weighted the lowest with 5/100.
The rubric was built on a simple 0-3 scoring scale for each category. A 0 score meant there was no mention, and each natural-number increase indicated more context about the topic, with a full score of 3 indicating that the topic was addressed with data and future plans. In general, the rubric was:
0: No mention
1: Mention
2: Mention with some details
3: Mention with data and reference to future plans
For example, if a company mentions “renewable energy” once without any supporting scientific data, it would receive a 1. However, if there were supporting data, such as energy usage metrics (e.g., total electricity consumption in MWh), a description of the renewable energy mix, and future plans, it would receive a score of 3. If any of the metrics are missing, the points gradually decrease.
Mentioning means: appearance of keywords identified for the appropriate category. For example, keywords for the Energy & Electricity Use category include:

Rubric Progression and Iterative Refinement

The base rubric was a solid starting point, yet as ESG reports are not uniform, we encountered some issues. After some analysis, it became clear that we needed to be more specific. Companies were using similar language; however, they weren't providing sufficient detail, and it was hard to gauge what constituted sufficient detail.2
We also reviewd the Worldwide AI Ethics Review paper by Correa et al. This study is a meta-analysis of 200 different AI governance policies and ethical guidelines from around the world. The authors identified 17 resonating principles that frequently appear in these documents, such as transparency, accountability, and sustainability. A key finding of the paper is the “AI ethics boom,” where an explosion of voluntary guidelines has created a fragmented landscape with no single global consensus.
Since the original rubric was broad, we made it more detailed and added subcategories. V1 of the Rubric had no subcategories, and thus, our results and scoring felt lacking. This was very helpful for categories such as energy use, emissions, and water management because there is a diversity of methods and metrics that address these areas.
To make the rubric more operational, we implemented a keyword searching feature. Most ESG reports are too long and full of fluff, so to get exactly the line we need, we used a keyword search. Since we are going to use NLPs to analyze the grading structure, this part saved us a lot of time and improved the quality of our evaluations. For each category and subcategory, we developed ESG report terminology and unit indicators.
After getting a keyword match, we needed to figure out how to capture context and specificity. This is important because, under our rubric, merely mentioning it is insufficient and should be scored lower than an ESG report with more detail. This part was going to rely heavily on NLPs and training them according to the rubric.
Technical Details: NLP Pipeline
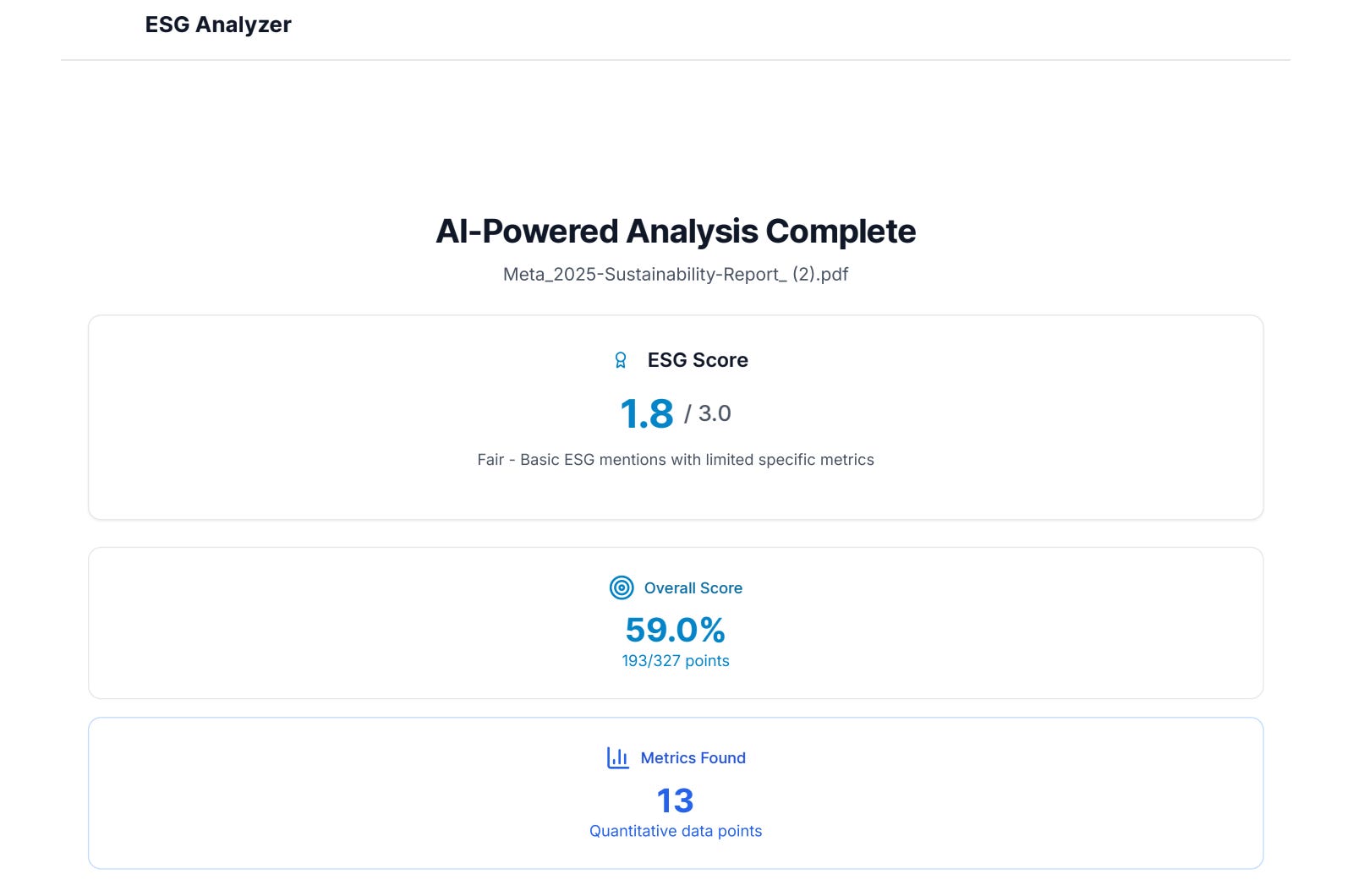
Now that we had a proper rubric to go by, it was time to build a lightweight NLP pipeline to apply it to any ESG report. As stated, ESG reports are long, unstructured, and inconsistent with the information they provide. The goal was to create a website where simply dropping in a PDF would generate a detailed scoring report based on the rubric.
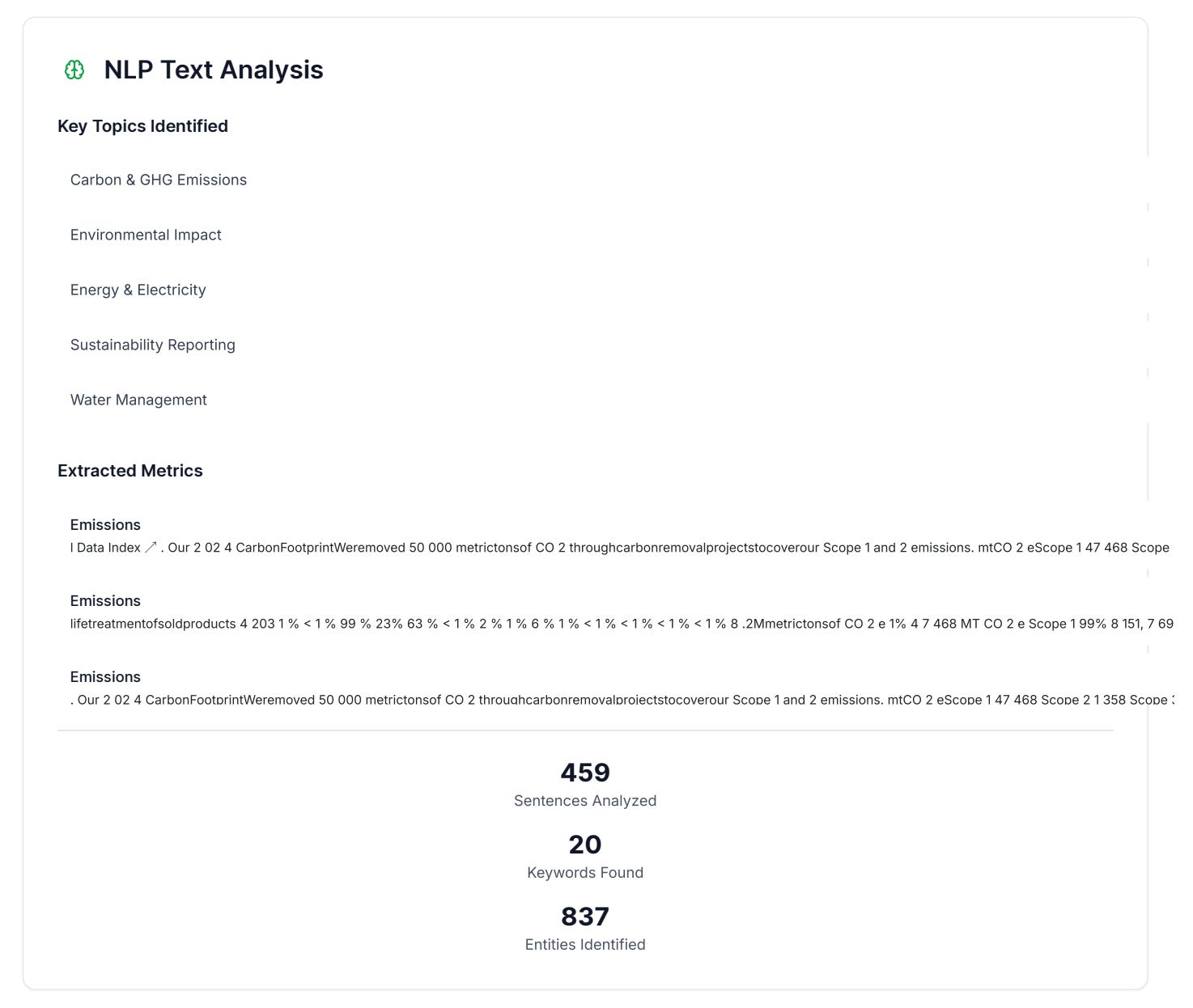
The first part of this was text normalization of the ESG report to extract raw text. Most ESG reports include various graphs, charts, and other compelling ways to present the data. To address this, a normalization step is performed before raw text extraction, removing whitespace and line breaks and formatting the graphs. This ensures that energy usage tables, water content, and emission values are properly analyzed.
Once we have text, we can perform sentence segmentation. The document is divided into individual sentences, and instead of analyzing the whole report, only the sentences are analyzed. It doesn’t matter whether it’s a sentence with a lot of fluff or a concise one; both are analyzed in the dataset.
There is also a keyword and topic extraction step that identifies words related to specific categories. This step helps identify which keywords appear most frequently and narrow down the sentences we need to analyze.
Following keyword extraction, there is also a metric extraction step that follows the same idea. The goal is to pinpoint the quantitative metrics so that we can determine if they have data-backed disclosures.
There is also a lightweight semantic matching step that runs with this process because the same thing can be interpreted differently. The example phrases and keywords in the rubric are cross-checked with this scan using the Jaccard similarly. This simple technique helps the model express the same idea even with different wording to narrow the sentences.
After all the preparation, we can start the topic classification and run it through the rubric scoring engine. Here, we assign sentences to categories and subcategories, which concludes the NLP analysis. We then pass it through the scoring engine, which evaluates the sentences based on the rubric and assigns a score to each category. This is then averaged to produce a final output showing all categories, scores, and reasons for each score.
Final Version
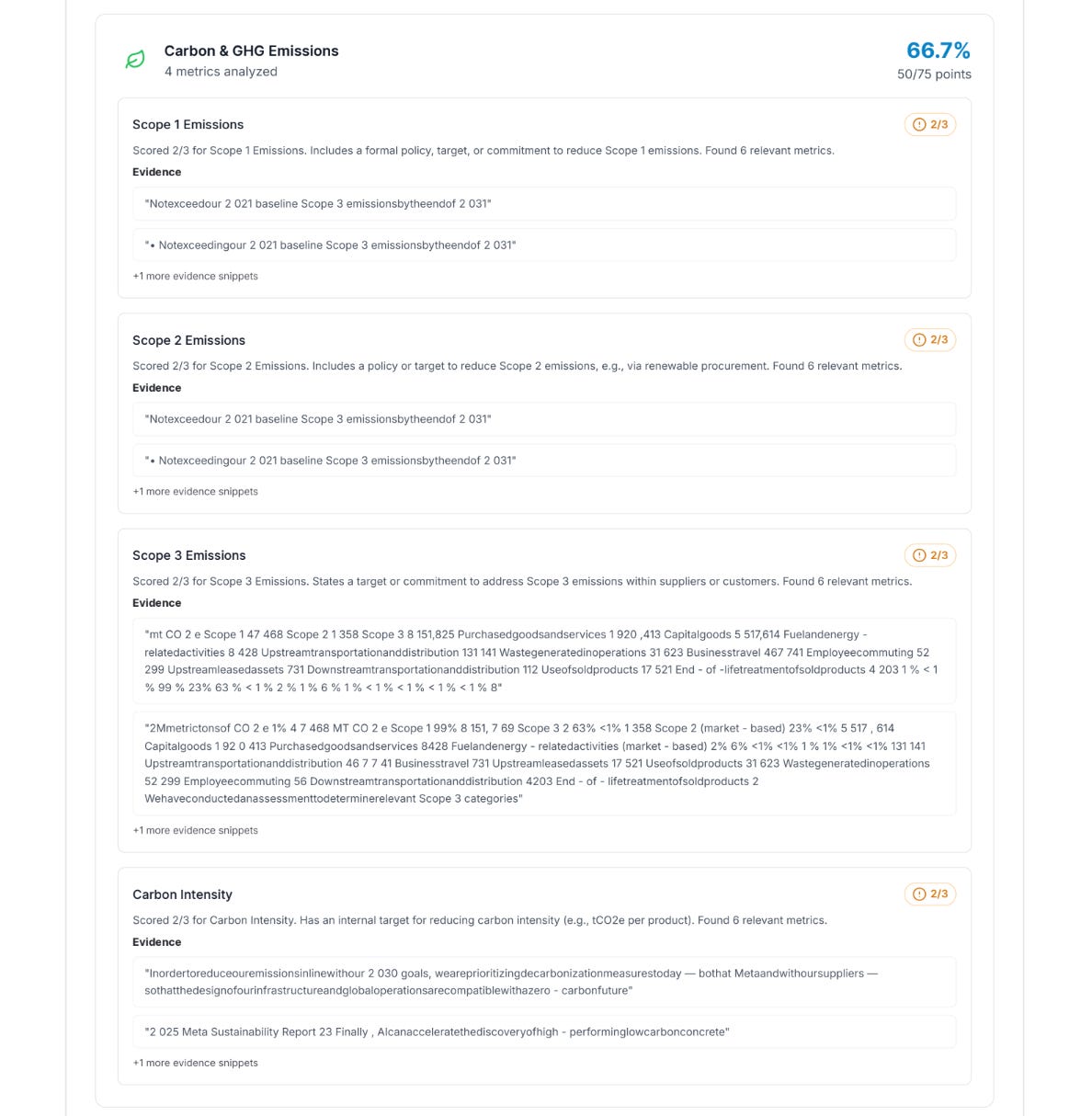
Reflections & Future Directions
The hardest part of this project was defining and measuring “Ethics,” which is interpreted in different ways. The rubric is my attempt to structure scoring for ESG reports, but it needs constant improvement. Every time I analyzed a new report, I came across new edge cases. Each time I encountered something, I had to go back to the rubric and tweak it to make it as accurate as possible. Even in the final product, the rubric is not complete; it was limited to the scope and time available during the internship.
Next Steps and Limitations
If this project were to continue, there are several areas for improvement.
One area could be to present the evidence more effectively. As shown in the report, the evidence is just condensed and included; if we could direct it to the exact section, it would be better. There could also be a replacement for the analyzer model that uses neural networks instead, or in addition to, of NLP, since neural networks can be more accurate. Another area would be improving the distinction in weightage for the existing metrics (Categories 1-4) and the professed alignment or forward-looking statements (Categories 5-6); in that, different weights may be more or less reasonable for a user’s actual needs.3 Additionally, the project would benefit from improvements for the user, such as having an accessible database of existing company reports and associated scoring.
Further specific issues are discussed below.
The Problem of Self-Reporting Disclosures
The fact that the EPA evaluates declared disclosures was also an inherent limitation of the project. When a report passes through the analyzer, its output is not a true evaluation of the company’s environmental impact, as it relies on self-reporting and limited pattern recognition. A company that is particularly environmentally conscious might score lower because its ESG reports are less comprehensive than those of a company that does less but has more expansive reporting. Company motivation depends heavily on what they are willing to share, and we can’t get the full context just from a report that’s not completely standardized.
Scoring Buckets
Another consideration is the utility of the current scoring buckets. The overall scoring categories are currently defined as the integers 0, 1, 2, and 3. Through iterative testing, we found that the boundary between 0 and 1 is the most reliable distinction the analyzer makes: either a topic is present, or it is not. The boundaries between 1, 2, and 3 are less stable. This is consistent with a well-documented pattern in NLP and annotation research: as the number of ordinal categories increases, scoring consistency tends to decrease (Crible & Degand, 2019). Finer-grained scales demand subtler judgments from annotators and automated systems alike, and those subtler judgments are more susceptible to variation across documents, phrasings, and report styles.
Research on text annotation has similarly found that rating scale design is itself a source of bias, and that simpler scales with clearly differentiated levels tend to produce more reliable results than scales where middle categories blur together (Alm & Sproat, 2005; Kiritchenko & Mohammad, 2017). For this reason, we have considered collapsing the scale to three categories: 0 (no mention), 1 (mention without substantive elaboration), and 2 (mention with data, context, or forward-looking commitments). This would sacrifice some descriptive resolution but would produce scores whose distinctions are more meaningful and reproducible, particularly for an automated pipeline that relies on keyword matching and lightweight semantic similarity rather than deep reading comprehension.
Final Thoughts
Overall, this project substantially changed my views on sustainability and ethics. The main thing I learned was the importance of continuous refinement. Since ethics is so broad, there was no single correct answer, and throughout this process, I just picked a path and kept refining it. My mentor played a huge role in the project because it involved a lot of decision-making that needed a second opinion to work towards a solution. At the end of the day, this was my attempt to improve the fight for sustainability, and regulating ESG reports is a definitive step towards that goal.
This project focuses on technology companies because their ESG reports contain extensive data on energy use, emissions, and infrastructure. Even with discrepancies between the reports, they generally highlight the same metrics and topics, making it easier to categorize. Of course, this leads to a bias towards this ESG analyzer being more accurate when testing on technologies.
The rubric underwent multiple refinements, tracked in a spreadsheet, addressing all the inconsistencies we found. Different companies described similar topics differently. There were also different levels of explanation for the same topic, so we went back and adjusted what constitutes a set of scores. All of this was done based on what makes logical sense, which means it’s not perfect, but since there is no standard, this is the best we could do.
The current weighting privileges measurable environmental performance (Categories 1-4) over stated intentions and framework alignment (Categories 5-6). This reflects a defensible priority, but not a neutral one. A regulator or greenwashing investigator would likely want quantitative metrics weighted even more heavily; an ESG investor might foreground forward-looking commitments as signals of strategic direction; a disclosure researcher might care most about which reporting frameworks a company adopts. Under the current scheme, a company with robust emissions data but vague commitments can score similarly to one with thin data but strong framework alignment, and different weightings would pull those cases apart in ways that matter. User-adjustable weights could address this, though at a cost to the tool’s simplicity and cross-report comparability. For a recent ambitious attempt to navigate tension between standardization and evaluative flexibility at scale, see MIT Media Lab’s AHA Open Benchmark for the Human Impact of AI, a collaboration with USC and UC Berkeley that developed multi-dimensional evaluation frameworks with input from over 80 interdisciplinary experts.
 | A guest post by
|